本文首发于微信订阅号「沃趣技术」,转载时请注明来源。
本文将从初学者角度,介绍 Linux 内核如何接收网络帧:从网卡设备完成数据帧的接收开始,到数据帧被传递到网络栈中的第三层结束。重点介绍内核的工作机制,不会深入过多代码层面的细节,示例代码来自 Linux 2.6。
设备的通知手段
从计算机硬件的角度,一个数据帧从进入网卡到最后被内核网络栈处理的整体示意图如下:
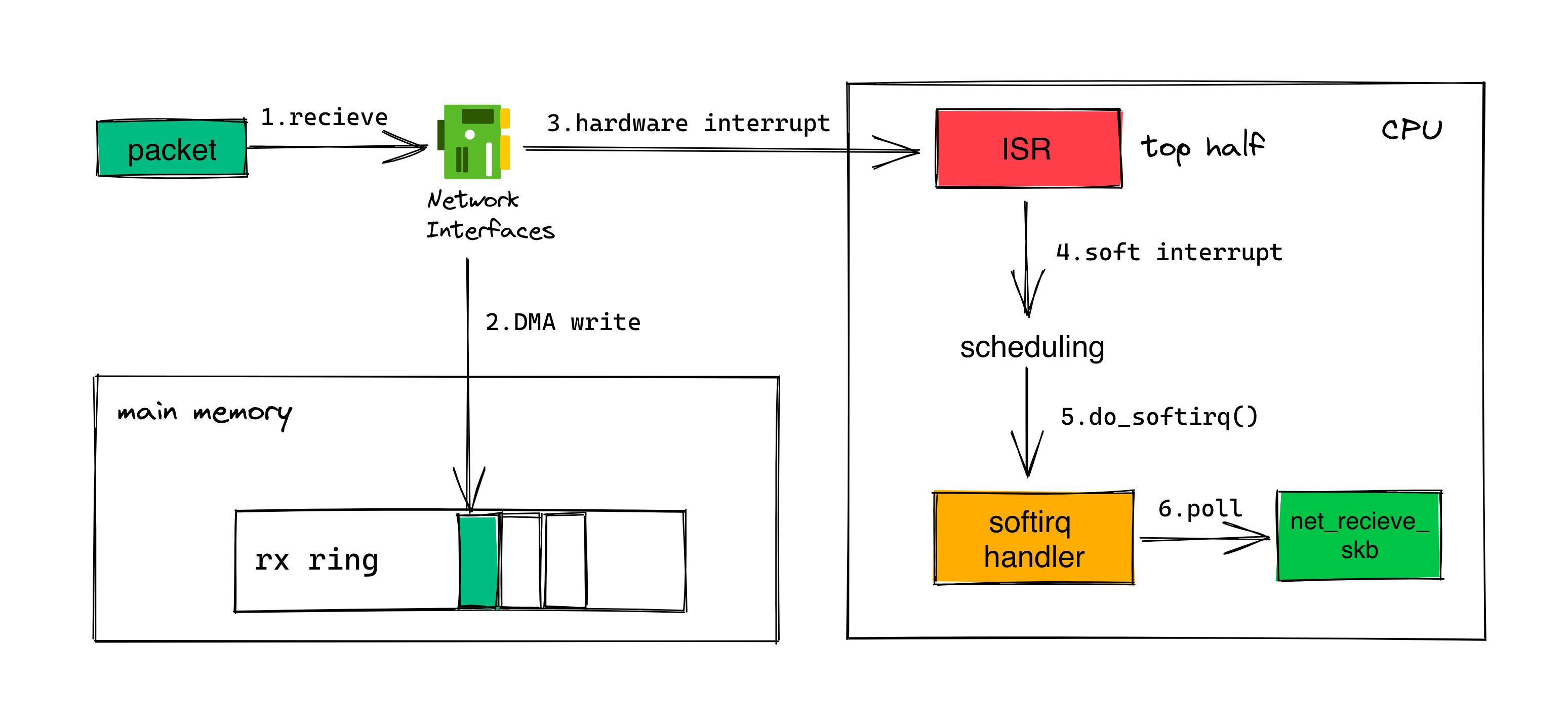
当网卡设备完成一个数据帧的接收后,可能将数据帧暂存于设备内存,也可能通过 DMA(Direct memory access) 直接写入到主内存的接收环(rx ring),接下来必须通知操作系统内核对已接收的数据进行处理。
下面将讨论几种可能的通知手段。
轮询
轮询(Polling)指的是由内核主动地去检查设备,比如定期读取设备的内存寄存器,判断是否有新的接收帧需要处理。这种方式在设备负载较高时响应效率低,在设备负载低时又占用系统资源,操作系统很少单独采用,结合其他机制后才能实现较理想的效果。
硬件中断
当接收到新的数据帧等事件发生时,设备将生成一个硬件中断信号。该信号通常由设备发送给中断控制器,由中断控制器分发给 CPU。CPU 接受信号后将从当前执行的任务中被打断,转而执行由设备驱动注册的中断处理程序来处理设备事件。中断处理程序会将数据帧拷贝到内核的输入队列中,并通知内核做进一步处理。这种技术在低负载时表现良好,因为每一个数据帧都会得到及时响应,但在负载较高时,CPU 会被频繁的中断从而影响到其他任务的执行。
对接收帧的处理通常分为两个部分:首先驱动注册的中断处理程序将帧复制到内核可访问的输入队列中,然后内核将其传递给相关协议的处理程序直到最后被应用程序消费。第一部分的中断处理程序是在中断上下文中执行的,可以抢占第二部分的执行,这意味着复制接收帧到输入队列的程序比消费数据帧的协议栈程序有更高的优先级。
在高流量负载下,中断处理程序会不断抢占 CPU。后果显而易见:输入队列最终将被填满,但应该去出队并处理这些帧的程序处于较低优先级没有机会执行。结果新的接收帧因为输入队列已满无法加入队列,而旧的帧因为没有可用的 CPU 资源不会被处理。这种情况被称为接收活锁(receive-livelock)。
硬件中断的优点是帧的接收和处理之间的延迟非常低,但在高负载下会严重影响其他内核或用户程序的执行。大多数网络驱动会使用硬件中断的某种优化版本。
一次处理多个帧
一些设备驱动会采用一种改良方式,当中断处理程序被执行时,会在指定的窗口时间或帧数量上限内持续地入队数据帧。由于中断处理程序执行时其他中断将被禁用,因此必须设置合理的执行策略来和其他任务共享 CPU 资源。
该方式还可进一步优化,设备仅通过硬件中断来通知内核有待处理的接收帧,将入队并处理接收帧的工作交给内核的其他处理程序来执行。这也是 Linux 的新接口 NAPI 的工作方式。
计时中断
除了根据事件立刻生成中断,设备也可在有接收帧时,以固定的间隔发送中断,中断处理程序将检查这段间隔时间内是否有新的帧,并一次性处理它们。如果所有接收帧已经处理完毕并且没有新的帧,设备会停止发送中断。
这种方式要求设备在硬件层面实现计时功能,而且根据计时间隔长短会带来固定的处理延迟,但在高负载时可以有效地减少 CPU 占用并且避免接收活锁。
在实践中的组合
不同的通知机制有其适合的工作场景:低负载下纯中断模型保证了极低延迟,但在高负载下表现糟糕;计时中断在低负载下可能会引入过高延迟并浪费 CPU 时间,但在高负载下对减少 CPU 占用和解决接收活锁有很大帮助。在实践中,网络设备往往不依赖某种单一模型,而是采取组合方案。
以 Linux 2.6 Vortex 设备所注册的中断处理函数 vortex_interrupt (位于 /drivers/net/3c59x.c)为例:
- 设备会将多个事件归类为一种中断类型(甚至还可以在发送中断信号前等待一段时间,将多个中断聚合成一个信号发送)。中断触发
vortex_interrupt的执行并禁用该 CPU 上的中断。 - 如果中断是由接收帧事件
RxComplete引发,处理程序调用其他代码处理设备接收的帧。 vortex_interrupt在执行期间持续读取设备寄存器,检查设备是否有新的中断信号发出。如果有且中断事件为RxComplete,处理程序将继续处理接收帧,直到已处理帧的数量达到预设的work_done值才结束。而其他类型的中断将被处理程序忽略。
软中断处理机制
当硬件中断信号到达 CPU 后,需要通过合理的任务调度机制,才能以较低延迟处理接收帧,又避免接收活锁和饥饿等资源抢占问题。
一个中断通常会触发以下事件:
- 设备产生一个中断并通过硬件通知内核。
- 如果内核没有正在处理另一个中断(即中断没有被禁用),它将收到这个通知。
- 内核禁用本地 CPU 的中断,并执行与收到的中断类型相关联的处理程序。
- 内核退出中断处理程序,重新启用本地 CPU 的中断。
CPU 在执行中断号对应处理程序的期间处于中断上下文,中断会被禁用。这意味着 CPU 在处理某个中断期间,它既不会处理其他中断,也不能被其他进程抢占,CPU 资源由该中断处理程序独占。这种设计决定减少了竞争条件的可能性,但也带来了潜在的性能影响。
显然,中断处理程序应当尽可能快地完成工作。不同的中断事件所需要的处理工作量并不相同,比如当键盘的按键被按下时,触发的中断处理函数只需要将该按键的编码记录下来,而且这种事件的发生频率不会很高;而处理网络设备收到的新数据帧时,需要为 skb 分配内存空间,拷贝接收到的数据,同时完成一些初始化工作比如判断数据所属的网络协议等。
为了尽量减少 CPU 处于中断上下文的时间,操作系统为中断处理程序引入了上、下半部的概念。
下半部处理程序
即使由中断触发的处理动作需要大量的 CPU 时间,大部分动作通常是可以等待的。中断可以第一时间抢占 CPU 执行,因为如果操作系统让硬件等待太长时间,硬件可能会丢失数据。这既适用于实时的数据,也适用于在固定大小缓冲区中存储的数据。如果硬件丢失了数据,一般没有办法再恢复(不考虑发送方重传的情况)。 另一方面,内核或用户空间的进程被推迟执行或抢占时,一般不会有什么损失(对实时性有极高要求的系统除外,它需要用完全不同的方式来处理进程和中断)。
鉴于这些考虑,现代中断处理程序被分为上半部和下半部。上半部分执行在释放 CPU 资源之前必须完成的工作,如保存接收的数据;下半部分则执行可以在推迟到空闲时完成的工作,如完成接收数据的进一步处理。
你可以认为下半部是一个可以异步执行的特定函数。当一个中断触发时,有些工作并不要求马上完成,我们可以把这部分工作包装为下半部处理程序延后执行。 上、下半部工作模型可以有效缩短 CPU 处于中断上下文(即禁用中断)的时间:
- 设备向 CPU 发出中断信号,通知它有特定事件发生。
- CPU 执行中断相关的上半部处理函数,禁用之后的中断通知,直到处理程序完成工作: a. 将一些数据保存在内存中,用于内核在之后进一步处理中断事件。 b. 设置一个标志位,以确保内核知道有待处理的中断。 c. 在终止之前重新启用本地 CPU 的中断通知。
- 在之后的某个时间点,当内核没有更紧迫的任务处理时,会检查上半部处理程序设置的标志位,并调用关联的下半部分处理程序。调用之后它会重置这个标志位,进入下一轮处理。
Linux 为下半部处理实现了多种不同的机制:软中断、微任务和工作队列,这些机制同样适用于操作系统中的延时任务。下半部处理机制通常都有以下共同特性:
- 定义不同的类型,并在类型和具体的处理任务之间建立关联。
- 调度处理任务的执行。
- 通知内核有已调度的任务需要执行。
接下来着重介绍处理网络数据帧用到的软中断机制。
软中断
软中断有以下几种常用类型:
|
|
其中 NET_TX_SOFTIRQ 和 NET_RX_SOFTIRQ 用于处理网络数据的接收和发送。
调度与执行时机
每当网络设备接收一个帧后,会发送硬件中断通知内核调用中断处理程序,处理程序通过以下函数在本地 CPU 上触发软中断的调度:
__raise_softirq_irqoff:在一个专门的 bitmap (位图)结构中设置与软中断类型对应的比特位,当后续对该比特位的检查结果为真时,调用与软中断关联的处理程序。每个 CPU 使用一个单独的 bitmap。raise_softirq_irqoff:内部包装了__raise_softirq_irqoff函数。如果此函数不是从中断上下文中调用,且抢占未被禁用,将会额外调度一个ksoftirqd线程。raise_softirq: 内部包装了raise_softirq_irqoff,但执行时会禁用 CPU 中断。
在特定的时机,内核会检查每个 CPU 独有的 bitmap 判断是否有已调度的软中断等待执行,如果有将会调用 do_softirq 处理软中断。内核处理软中断的时机如下:
-
do_IRQ
每当内核收到一个硬件中断的 IRQ 通知时,会调用
do_IRQ来执行中断对应的处理程序。中断处理程序中可能会调度新的软中断,因此在do_IRQ结束时处理软中断是一个很自然的设计,也可以有效的降低延迟。此外,内核的时钟中断还保证了两次软中断处理时机之间的最大时间间隔。大部分架构的内核会在退出中断上下文步骤
irq_exit()中调用do_softirq:1 2 3 4 5 6 7 8 9 10 11 12 13unsigned int __irq_entry do_IRQ(struct pt_regs *regs) { ...... exit_idle(); irq_enter(); // handle irq with registered handler irq_exit(); set_irq_regs(old_regs); return 1; }在
irq_exit()中,如果内核已经退出中断上下文且有待执行的软中断,将调用invoke_softirq():1 2 3 4 5 6 7 8 9 10 11 12void irq_exit(void) { account_system_vtime(current); trace_hardirq_exit(); sub_preempt_count(IRQ_EXIT_OFFSET); if (!in_interrupt() && local_softirq_pending()) invoke_softirq(); rcu_irq_exit(); preempt_enable_no_resched(); }invoke_softirq是对do_softirq的简单封装:1 2 3 4 5 6 7static inline void invoke_softirq(void) { if (!force_irqthreads) do_softirq(); else wakeup_softirqd(); } -
从中断和异常事件(包括系统调用)返回时,这部分处理逻辑直接写入了汇编代码。
-
调用
local_bh_enable开启软中断时,将执行待处理的软中断。 -
每个处理器有一个软中断线程 ksoftirqd_CPUn,该线程执行时也会处理软中断。
软中断执行时 CPU 中断是开启的,软中断可以被新的中断挂起。但如果软中断的一个实例已经在一个 CPU 上运行或挂起,内核将禁止该软中断类型的新请求在 CPU 上运行,这样可以大幅减少软中断所需的并发锁。
软中断的处理
当执行软中断的时机达成,内核会执行 do_softirq 函数。
do_softirq 首先会将待执行的软中断保存一份副本。在 do_softirq 运行时,同一个软中断类型有可能被调度多次:运行软中断处理程序时可以被硬件中断抢占,处理中断时期间可以重新设置 cpu 的待处理软中断 bitmap,也就是说,在执行一个待处理的软中断期间,这个软中断可能会被重新调度。出于这个原因,do_softirq 会首先禁用中断,将待处理软中断的 bitmap 保存一份副本到局部变量 pending 中,然后将本地 CPU 的软中断 bitmap 中对应的位重置为 0,随后重新开启中断。最后,基于副本 pending 依次检查每一位是否为 1,如果是则根据软中断类型调用对应的处理程序:
|
|
等待中的软中断调用次序取决于位图中标志位的位置以及扫描这些标志的方向(由低位到高位),并不是以先进先出的方式执行的。
当所有的处理程序执行完毕后,do_softirq 再次禁用中断,并重新检查 CPU 的待处理中断 bitmap,如果发现又有新的待处理软中断,则再次创建一份副本重新执行上述流程。这种处理流程最多会重复执行 MAX_SOFTIRQ_RESTART 次(通常值为 10),以避免无限抢占 CPU 资源。
当处理轮次到达 MAX_SOFTIRQ_RESTART 阈值时,do_ softirq 必须结束执行,如果此时依然有未执行的软中断,将唤醒 ksoftirqd 线程来处理。但是 do_softirq 在内核中的调用频率很高,实际上后续调用的 do_softirq 可能会在 ksoftirqd 线程被调度之前就处理完了这些软中断。
ksoftirqd 内核线程
每个 CPU 都有一个内核线程 ksoftirqd(通常根据 CPU 序号命名为 ksoftirqd_CPUn),当上文描述的机制无法处理完所有的软中断时,该 CPU 位于后台的 ksoftirqd 线程被唤醒,并承担起在获得调度后尽可能多的处理待执行软中断的职责。
ksoftirqd 关联的任务函数 run_ksoftirqd 如下:
|
|
ksoftirqd 做的事情和 do_softirq 基本相同,其主要逻辑是通过 while 循环不断的调用 __do_softirq (该函数也是 do_softirq 的核心逻辑),只有达到以下两种条件时才会停止:
- 没有待处理的软中断时,此时 ksoftirqd 会调用
schedule()触发调度主动让出 CPU 资源。 - 该线程执行完毕被分配的时间分片,被要求让出 CPU 资源等待下一次调度。
ksoftirqd 线程设置的调度优先级很低,同样可以避免软中断较多时抢占过多的 CPU 资源。
网络帧的接收
在 do_softirq 中,内核通过执行 h->action(h); 调用该软中断类型所注册的处理程序,本文仅关注与接收网络帧相关的软中断处理程序。
Linux 的网络系统主要使用以下两种软中断类型:
- NET_RX_SOFTIRQ 用于处理接收(入站)网络数据
- NET_TX_SOFTIRQ 用于处理发送(出栈)网络数据
NET_RX_SOFTIRQ 软中断处理程序接收网络帧的整体流程示意如下:
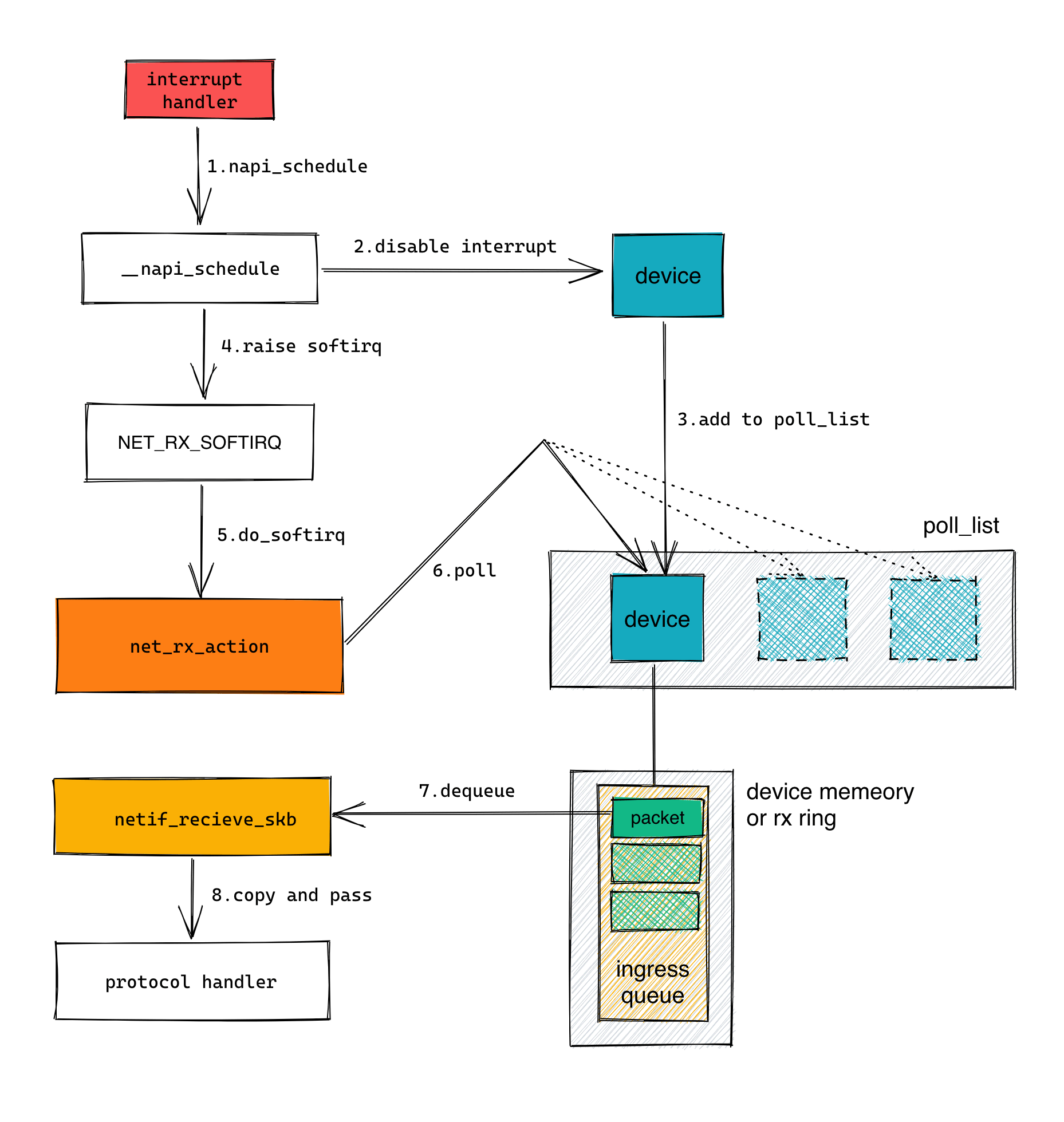
在了解具体的软中断处理程序之前,我们还需要结合 Linux 的具体实现重新回顾上文介绍过的通知处理机制。
Linux New API (NAPI)
网卡设备每接收到一个二层的网络帧后,使用硬件中断来向 CPU 发出信号,通知其有新的帧需要处理。收到中断的CPU会执行 do_IRQ 函数,调用与硬件中断号关联的处理程序。处理程序通常是由设备驱动程序在初始化时注册的一个函数,这个中断处理程序将在禁用中断模式下执行,使得 CPU 暂时停止接收中断信号。
中断处理程序会执行一些必要的即时任务,并将其他任务调度到下半部中延迟执行。在 Linux 中,具体来说中断处理程序会做这些事情:
- 将网络帧复制到
sk_buff数据结构中。 - 初始化一些
sk_buff的参数,供上层的网络栈使用。特别是skb->protocol,它标识了上层的协议处理程序。 - 更新其他的设备专用参数。
- 通过调度软中断 NET_RX_SOFTIRQ 来通知内核进一步处理接收帧。
我们上文介绍过轮询和中断通知机制(包括几种改良版本),它们有不同的优缺点,适用不同的工作场景。Linux 在 Linux v2.6 引入了一种混合了轮询和中断的 NAPI 机制来通知并处理新的接收帧。NAPI 在高负载场景下有良好表现,还能显著的节省 CPU 资源。本文将重点介绍 NAPI 机制。
当设备驱动支持 NAPI 时,设备在接收到网络帧后依然使用中断通知内核,但内核在开始处理中断后将禁用来自该设备的中断,并持续地通过轮询方式从设备的输入缓冲区提取接收帧进行处理,直到缓冲区为空时,结束处理程序的执行并重新启用该设备的中断通知。NAPI 结合了轮询和中断的优点:
- 空闲状态下,内核既不需要浪费资源去做轮询,也能在设备接收到新的网络帧后立刻得到通知。
- 内核被通知在设备缓冲区有待处理的数据之后,不需要再浪费资源去处理中断,简单通过轮询去处理这些数据即可。
对内核来说,NAPI 有效减少了高负载下需要处理的中断数量,因此降低了 CPU 占用,此外通过轮询地方式去访问设备,也能够减少设备之间的争抢。
内核通过以下数据结构来实现 NAPI:
poll:用于从设备的入站队列中出队网络帧的虚拟函数,每个设备都会有一个单独的入站队列。poll_list: 一个维护处于轮询中状态设备的链表。多个设备可以共用同一个中断信号,因此内核需要轮询多个设备。加入到列表之后来自该设备的中断将被禁用。quota和weight:内核通过这两个值来控制每次从设备中出队数据的数量,quota 数量越小意味不同设备的数据帧更有机会得到公平的处理机会,但内核会花费更多的时间在设备之前切换,反之依然。
当设备发送中断信号且被接收之后,内核执行该设备驱动注册的中断处理程序。中断处理程序将调用 napi_schedule 来调度轮询程序的执行。在 napi_schedule 中,如果发送中断的设备未在 CPU 的 poll_list 中,内核将其加入到 poll_list,并通过 __raise_softirq_irqoff 触发 NET_RX_SOFTIRQ 软中断的调度。其主要逻辑位于 ____napi_schedule 中:
|
|
输入队列
每个 CPU 都有一个存放接收网络帧的输入队列 input_pkt_queue,这个队列位于 softnet_data 结构中:
|
|
但并不是所有的网卡设备驱动都会使用这个输入队列,对于使用 NAPI 机制的网卡,每个设备都有一个单独的输入队列。这个输入队列可能位于设备内存,也可能是主内存中的接收环。
接收帧软中断处理程序
NET_RX_SOFTIRQ 的处理程序是 net_rx_action。其部分代码如下:
|
|
当 net_rx_action 被调度执行后:
- 从头开始遍历
poll_list链表中的设备,调用设备的poll虚拟函数处理入站队列中的数据帧。我们将在下一节介绍该虚拟函数。 - poll 被调用时所处理的数据帧数量到达最大阈值后,即使该设备的入站队列还未被清空,也会将该设备移动到
poll_list的尾部,转而去处理poll_list中的下一个设备。 - 如果设备的入站队列被清空,调用
napi_complete将设备移出poll_list并开启该设备的中断通知。 - 一直执行该流程直到
poll_list被清空,或者net_rx_action执行完了足够的时间片(为了不过多占用 CPU 资源),这种情况退出前net_rx_action会重新调度自己的下一次执行。
Poll 虚拟函数
在设备驱动的初始化过程中,设备会将 dev->poll 指向由驱动提供的自定义函数,因此不同驱动会使用不同的 poll 函数。我们将介绍由 Linux 提供的默认 poll 函数 process_backlog,它的工作方式与大多数驱动的 poll 函数相似,其主要的区别在于,process_backlog 工作时不会禁用中断,由于非 NAPI 设备使用一个共享的输入队列,因此从输入队列中出栈数据帧时需要临时禁用中断以实现加锁;而 NAPI 设备使用单独的入站队列,且加入 poll_list 的设备会被单独禁用中断,因此在 poll 时不需要考虑加锁的问题。
process_backlog 执行时,首先计算出该设备的 quota。然后进入下面的循环流程:
- 禁用中断,从该 CPU 关联的输入队列中出栈数据帧,然后重新启用中断。
- 如果出栈时发现输入队列已空,则将该设备移出
poll_list,并结束执行。 - 如果输入队列不为空,调用
netif_receive_skb(skb)处理被出栈的数据帧,我们将在下一节介绍该函数。 - 检查以下条件,如果未满足条件则跳转到步骤 1 继续循环:
- 如果已出栈的数据帧数量达到该设备的 quota 值,结束执行。
- 如果已执行完了足够的 CPU 时间片,结束执行。
处理接收帧
netif_receive_skb 是 poll 虚拟函数用于处理接收帧的工具函数,它主要调用了 __netif_receive_skb(skb); 对数据帧依次进行一系列处理工作:
- 处理数据帧的 bond 功能。Linux 能够将一组设备聚合成一个 bond 设备,数据帧在进入三层处理之前,会在此将其接收设备
skb->dev更改为 bond 中的主设备。 - 传递一份数据帧副本给已注册的各个协议的嗅探程序。
- 处理一些需要在二层完成的功能,包括桥接。如果数据帧不需要桥接,继续向下执行。
- 传递一份数据帧副本给
skb->protocol对应的且已注册的三层协议处理程序。至此数据帧进入内核网络栈的更上层。
如果没有找到对应的协议处理程序或者未被桥接等功能消费,数据帧将被内核丢弃。
通常来说,三层协议处理程序会对数据帧作如下处理:
- 将它们传递给网络协议栈中更上层的协议如 TCP, UDP, ICMP,最后传递给应用进程。
- 在 netfilter 等数据帧处理框架中被丢弃。
- 如果数据帧的目的地不是本地主机,将被转发到其他机器。
对 Linux 如何接收网络帧的讨论到此结束,如果对数据帧在三层网络栈的处理流程感兴趣,可查看作者的另一篇文章 深入理解 netfilter 和 iptables。
参考链接
- Understanding Linux network internals-Christian Benvenuti -O'Reilly Media
- Linux 内核深度解析 - 余华兵